Introduction
Ever wondered if you could stream movies and series from anywhere in the world without having to pay big companies like Netflix, Amazon or Disney ? Those offer you a service that does not even let you choose the video quality! I personally wanted to implement a better solution myself. In this quick blog post series I will try to explain how I host my own private streaming platform. It runs using open source tools on top of my Kubernetes cluster running at home.
Thanks to my streaming setup I can specify the title of a movie or a serie, and it will try to download it, process it automatically and then make it available to be streamed via a web interface similar to Netflix. Multiple components make this work, I will try to explain in detail how they interract one with another.
The big picture
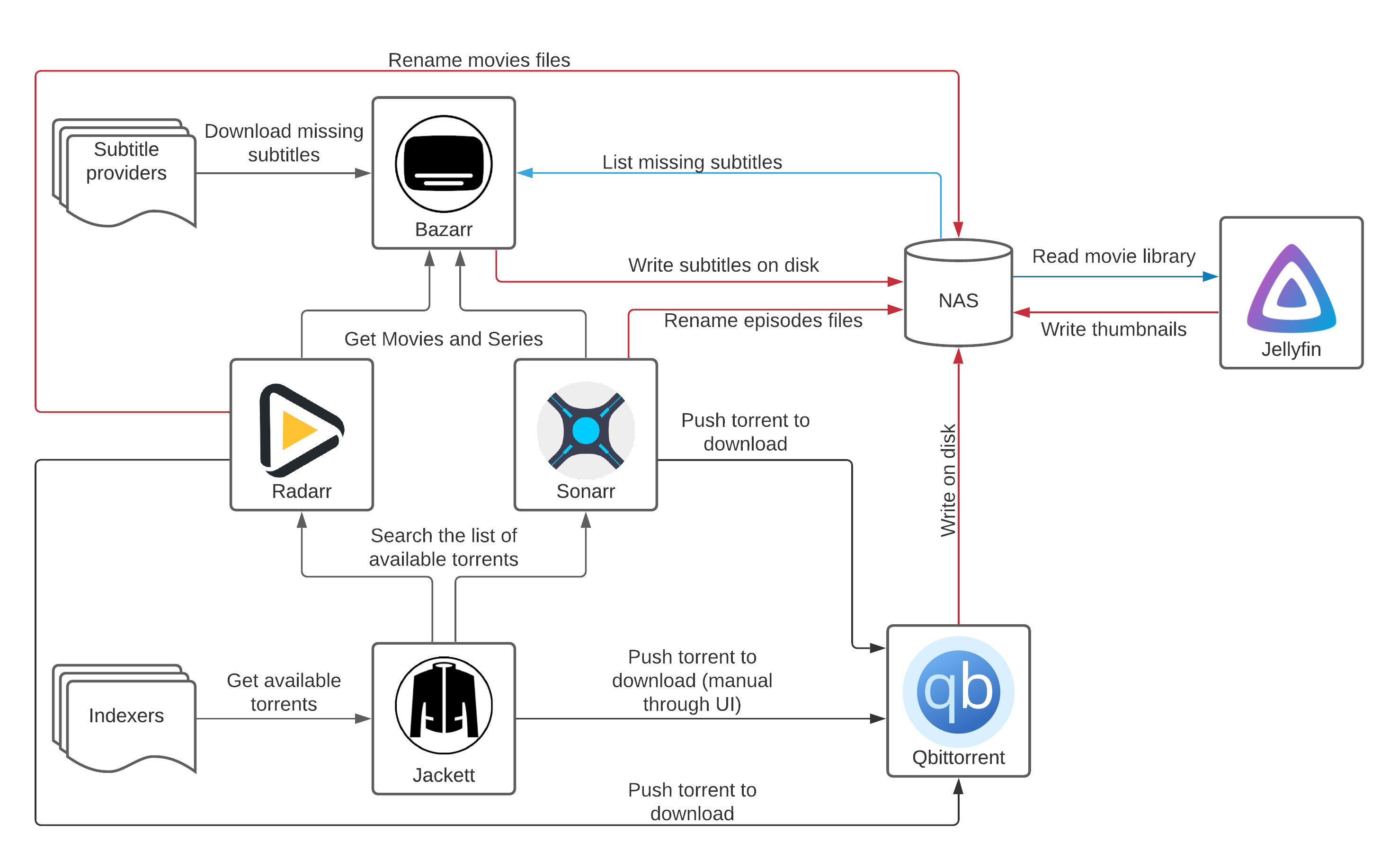
Streaming video files
Firstly Jellyfin is the video streaming platform it is similar to Plex and Emby. Jellyfin is a fork of Emby which is now partially closed source. This tool exposes a web interface through which it can stream video. Jellyfin indexes your Movies and Series libraries by detecting the corresponding metadata using tvdb, imdb… etc. Jellyfin also downloads thumbnails and the kind of metadata you would expect to find on a streaming service like Netflix, Prime video… It finds a quick description for the movie/episode and also displays the actors or voice over artists.
Jellyfin is the interface that the user interact with to view movies. All other components are tools that automate the download of the movies.
Managing the content library
Radarr/Sonarr are the services which are in charge of keeping track of which movies are already downloaded, searching the different indexers for missing movies/series. Radarr is tailored to downloading movies while Sonarr’s goal is to download series. Sonarr and Radarr periodically check for missing content and try to download them. If a download fails and multiple sources for the content are available, Sonarr or Radarr will try every source.
Finding the torrents
I tend to prefer downloading content via torrent, so I am using Jackett as indexer for Sonarr and Radarr. Jackett searches on multiple sites for magnet links or torrent files and package them in a way Sonarr and Radarr can understand. There is also a neat manual search feature that allows searching on multiple sites at once.
Downloading torrents
Qbittorrent is the service that is responsible for downloading torrents. Qbittorrent has a nice web UI that can be used to interact with downloads. Sonarr Radarr and Jackett can connect to this Qbittorrent instance in order to ask the download of a particular torrent. Sonarr and Radarr have a neat integration with the api of Qbittorrent however Jackett uses the “blackhole” method. Basically Jackett puts a torrent file inside a predefined directory, Qbittorrent watches this directory, start the download of the torrent and removes the torrent file from that directory.
Downloading subtitles
That’s all good and well but what if the downloaded movie does not have subtitles ? That’s when Bazarr comes into play. Bazarr regularly syncs itself with Sonarr and Radarr libraries and looks for downloaded content that do not have subtitles. If it finds some, it will try to search and download subtitles for the contents that currently do not have subtitles. However, a small problem arises: some downloaded subtitles do not match perfectly the audio/video track. It is surprisingly very common to have this kind of problem. Dealing with synchronization issues in Jellyfin is possible. We can add a manual offset on the subtitles, but it is super annoying to have to deal with this. Introducing ffsubsync ! This makes use of ffmpeg to extract the audio track and determine when actors are speaking, it makes a map of when people are currently speaking and then try to find the right offset on the subtitle file so that it matches the audio track. Then it rewrites the subtitle file after applying this offset. The great thing is that Bazarr now integrates well with ffsubsync. It has a neat boolean option called “Automatic Subtitles Synchronization”.
To see how I run this setup on my Kubernetes cluster, you can read my next blog post